
[Kafka] Kafka 훍어보기
2019-11-10 | Kafka왜 이름이 카프카인가?
제이 크렙스(Jay Kreps)가 말하길..
“카프카는 쓰기에 최적화된 시스템이므로 작가의 이름을 붙이는 것이 좋겠다고 생각했다. 나는 대학에서 문학을 수강하면서 프란츠 카프카를 좋아했다. 그래서 오픈 소스 프로젝트에 이름을 붙였더니 멋있었다.”
=> 멋있어 보여서
카프카의 탄생
- 링크드인의 내부 인프라 시스템으로 시작
- 2011초 아파치 공식 오픈소스로 공개
카프카가 왜 탄생되었는가?
AS-IS : end-to-end 연결방식의 아키텍처
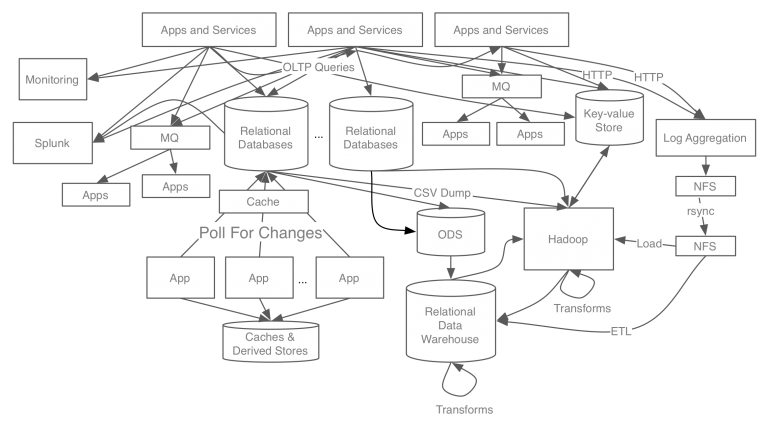
문제점
- 복잡도가 증가
- 데이터 파이프라인 관리의 어려움
복잡도가 늘고 파이프라인이 파편화되면서 개발이 지연되고 데이터를 신뢰할 수 없게 됨
TO-BE
목표
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템
모든 이벤트/데이터의 흐름을 중앙에서 관리하는 카프카를 적용한 결과
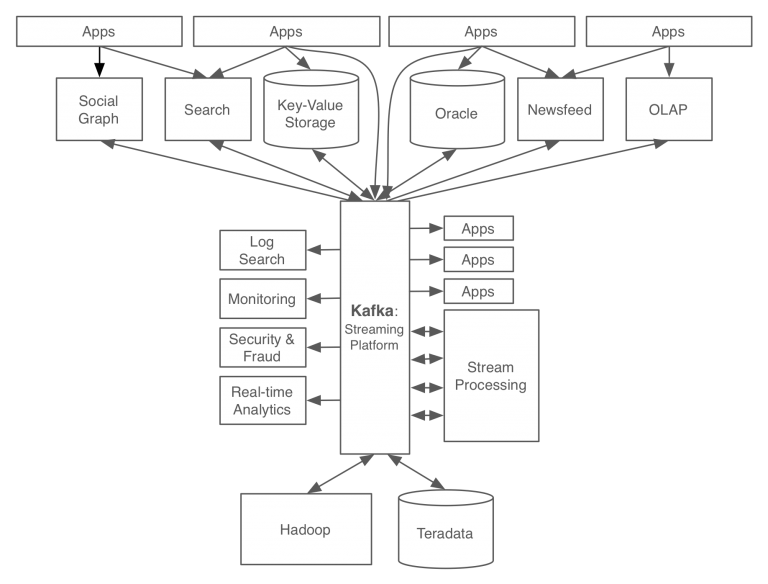
달라진 점
- 기존 데이터 스토어(ex. oracle, OLAP, key-value storage, treadata, hadoop)에 신규 데이터 스토어(social graph, search, newsfeed)가 들어와도 서로 카프카가 제공하는 표준 포맷으로 연결되어 있어서 데이터를 주고받는 데 부담이 없음.
- 다양한 분석(security & Fraud, Real-time Analytics, Stream Procession)이 가능해져 신뢰성 높은 데이터 분석뿐만 아니라 실시간 분석까지 가능해짐
데이터 스토어 백엔드 관리와 백엔드에 따른 포맷, 별도의 앱 개발 ==> 카프카에만 데이터를 전달하고 필요한 곳에서 각자 가져가서 데이터 처리
카프카 동작 방식
메시지 발행/구독 시스템
- 발행자는 브로커에게 메시지를 전송한다.
- 브로커는 발행된 메시지를 저장하고 구독중인 수신자에게 메시지를 중계한다.
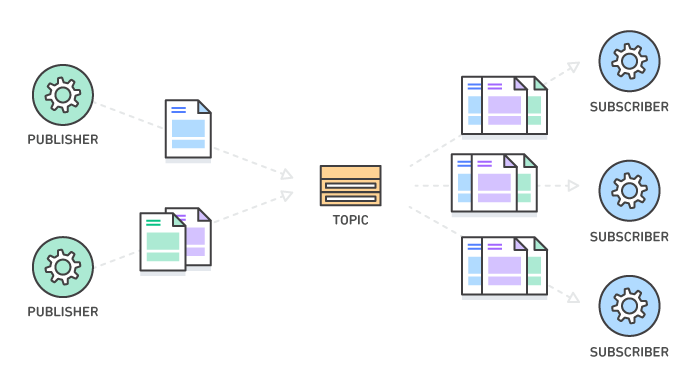
토픽과 파티션
- 카프카의 메시지는 토픽으로 분류된다.
- 하나의 토픽은 여러 개의 파티션으로 구성된다.

- 메시지는 파티션에 추가되며 맨 앞에서부터 끝까지 순서대로 읽을 수 있다.
- 하나의 토픽은 여러개의 파티션을 갖지만, 메시지 처리 순서는 토픽이 아닌 파티션별로 관리된다.
- 각 파티션은 서로 다른 서버에 분산될 수 있다.
- 파티션에 수록된 각 메시지는 고유한 오프셋을 갖는다.
Q. 왜 하나의 토픽을 파티셔닝하는가?
1개의 프로듀서가 1개의 파티션으로 4개 메시지 전송시 4초가 걸린다면(메시지당 1초라 가정)
4개의 파티션으로 4개의 메시지를 각 보내게 되면 총 1초가 걸리게 된다.
병렬처리를 할 수 있게 되어 성능상 이점은 있으나 순서보장이 되지 않게된다.
프로듀서와 컨슈머

프로듀서는
-
새로운 메시지를 생성한다
- 기본적으로 프로듀서는 메시지가 어떤 파티션에 수록되는지 관여하지 않는다.
- 하지만 때로는 프로듀서가 특정 파티션에 메시지를 직접 써야할 때는
메시지 키와파티셔너(partioner)를 사용한다
키를 기준으로 어떤 파티션에 해싱한다.
컨슈머는
- 메시지를 읽는다.
- 하나 이상의 토픽을 구독하여 메시지가 생성된 순서로 읽는다
- 메시지의 오프셋을 유지하여 읽는 메시지의 위치를 알 수 있다.
컨슈머 그룹은
- 하나 이상의 컨슈머로 구성된다.
- 한 토픽을 소비하기 위해 같은 그룹의 여러 컨슈머가 함께 동작한다.
- 한 토픽의 각 파티션은 한 컨슈머만 소비할 수 있다.
토픽 : 컨슈머 = n : 1

Consumer 0 은 파티션0의 offset 6
Consumer 1은 파티션1의 offset 5, 파티션2에서 offset 7
Consumer 3은 파티션3의 offset10
이렇게 각 컨슈머가 특정 파티션에 대응되는 것을 파티션 소유권(ownership)이라고 합니다
컨슈머 그룹 방식을 통해
- 다량의 메시지를 갖는 토픽을 소비할 때 컨슈머를 수평적으로 확장할 수 있고
- 한 컨슈머가 메시지 읽는 데 실패하더라도 같은 그룹의 다른 컨슈머가 파티션 소유권을 재조정받은 후 실패한 컨슈머의 파티션 메시지를 다시 읽을 수 있다.
브로커와 클러스터

브로커는
- 하나의 카프카 서버를 브로커라고 한다
- 브로커는 프로듀서로부터 메시지를 수신하고 오프셋을 지정한 후 해당 메시지를 디스크에 저장한다.
- 컨슈머의 파티션 읽기 요청에 응답하고 디스크에 수록된 메시지를 전송한다.
- 하나의 브로커 성능은 초당 수천 개의 토픽과 수백만 개의 메시지를 처리할 수 있다.
카프카 클러스터는
- 한 클러스터는 여러 개의 브로커로 구성된다.
왜 카프카를 사용할까?
다중 프로듀서와 다중 컨슈머
- 여러 클라이언트가 많은 토픽을 사용하거나 같은 토픽을 같이 사용해도 무리없이 많은 프로듀서의 메시지를 처리할 수 있다.
- 많은 컨슈머가 상호 간섭 없이 어떤 메시지 스트림도 읽을 수 있게 지원한다.

디스크 기반의 보존
- 메시지는 카프카 구성에 설정된 보존 옵션에 따라 디스크에 저장되어 보존된다.
- 프로듀서의 메시지 백업이 필요없고, 컨슈머가 중단되었다가 다시 실행되어도 중단 시점의 메시지부터 처리할 수 있다.
확장성
- 어떤 크기의 데이터도 쉽게 처리가 가능하다
- 여러 개의 브로커로 구성된 클러스터는 개별적인 브로커의 장애를 처리하면서 클라이언트에게 지속적인 서비스를 제공할 수 있다.
- 동시에 브로커에 장애가 생겨도 정상적으로 처리할 수 있는 복제 팩터(
replication factor)를 더 큰 값으로 지정하여 구성할 수 있다.
고성능
Kafka는 기존 메시징 시스템과는 달리 메시지를 메모리대신 파일 시스템에 쌓아두고 관리한다.
그런데 어떻게 고성능일 수 있을까?
-
Kafka는 메모리에 별도의 캐시를 구현하지 않고 OS의 페이지 캐시에 이를 모두 위임한다.
- OS가 알아서 서버의 유휴 메모리를 페이지 캐시로 활용하여 앞으로 필요할 것으로 예상되는 메시지들을 미리 읽어들여(readahead) 디스크 읽기 성능을 향상 시킨다.
- Kafka의 메시지는 하드디스크로부터 순차적으로 읽혀지기 때문에 하드디스크의 랜덤 읽기 성능에 대한 단점을 보완함과 동시에 OS 페이지 캐시를 효과적으로 활용할 수 있다.
메모리의 순차적 읽기 성능 > 하드디스크의 순차적 읽기 성능 > 메모리에 대한 랜덤 읽기
- 프로세스를 재시작 하더라도 OS의 페이지 캐시는 그대로 남아있기 때문에 프로세스 재시작 후 캐시를 워밍업할 필요가 없다는 장점도 있다.
-
메시지를 파일 시스템에 저장함으로써 얻는 부수적인 효과도 있다.
- 메시지를 메모리에 저장하지 않기 때문에 메시지가 JVM 객체로 변환되면서 크기가 커지는 것을 방지할 수 있다
- JVM의 GC로인한 성능저하 또한 피할 수 있다.
- Kafka에서는 파일 시스템에 저장된 메시지를 네트워크를 통해 consumer에게 전송할 때 zero-copy기법을 사용하여 데이터 전송 성능을 향상시켰다
reference
- http://www.confluent.io/blog/stream-data-platform-1
- https://epicdevs.com/17